Choose Your Model
Each new user receives 50 free credits to explore the platform when they get started with their Digital Twin. Once you are ready for more credits, you can set up a subscription plan or purchase a discounted credit bundle.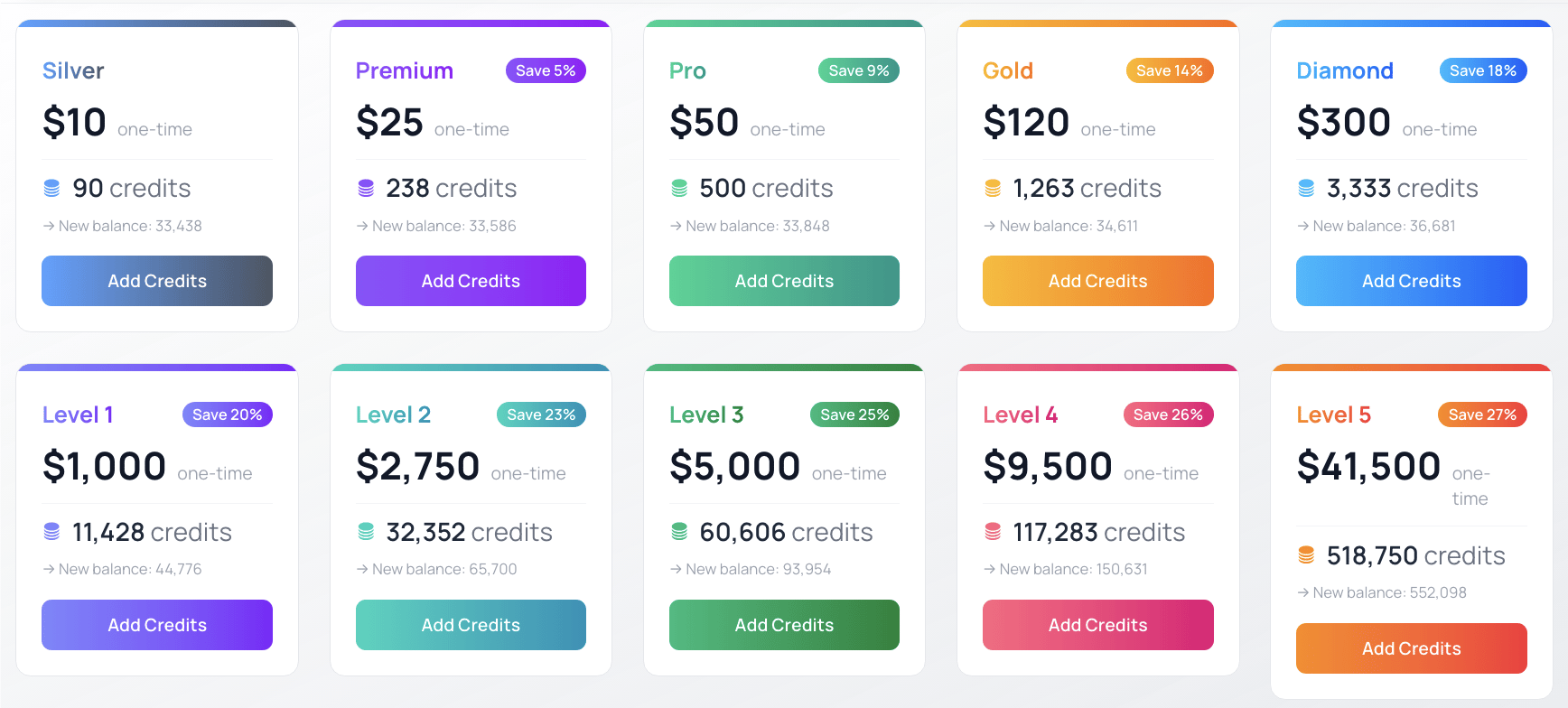
Per Credit Usage
The Per Credit Usage model allows you to buy bundles of credits and apply them to your personal account or to the Digital Twins you manage for your school or organization. Each interaction consumes credits based on the tokens it processes. Approximately 1 credit is used per 10,000 tokens of combined input and output, with a 1-credit minimum per AI call. Failed AI calls are never billed.Bring Your Own Keys (BYOK): Customers who provide their own Large Language Model API credentials (OpenAI, Anthropic, Gemini, Mistral, etc.) receive a substantial 40% discount on standard pricing, allowing you to maintain direct control over AI usage costs while leveraging your existing provider relationships and enterprise agreements. The discount applies to base service fees while standard setup and support charges remain unchanged. For details on connecting your own models, see Bring Your Own Model.
Credit Bundles
All credit packages are one-time purchases and credits never expire. Pricing starts at 11 cents per credit for the base tier, with increasing discounts as you purchase larger bundles. Savings percentages are calculated relative to the base rate of 11¢/credit.- Personal Credits
- Digital Twin Credits
Standard Packages for Personal Use
Select in the Gallery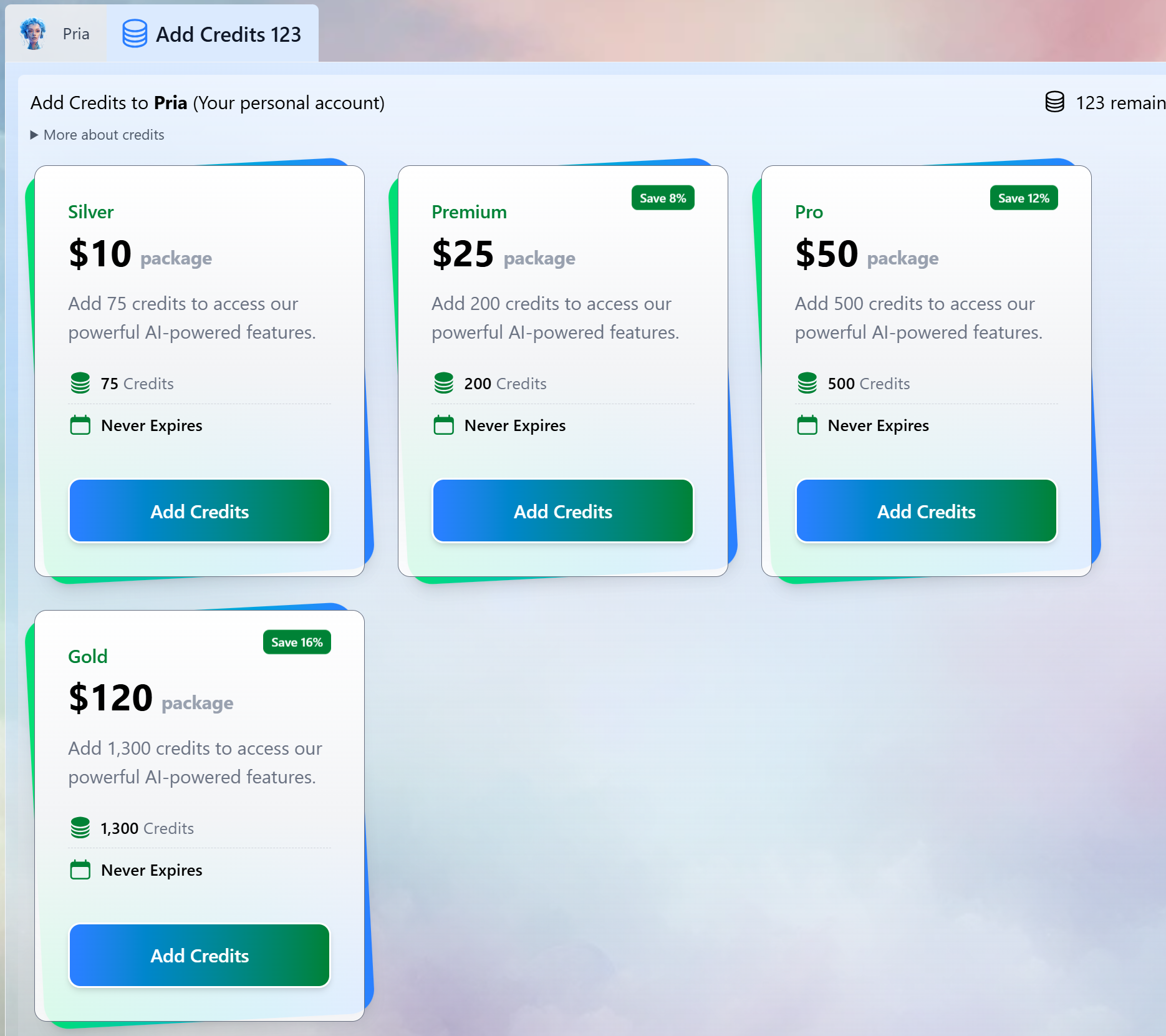
| Package | Price | Credits | Per Credit | Savings |
|---|---|---|---|---|
| Silver | $10 | 90 | 11.00¢ | — |
| Premium | $25 | 238 | 10.50¢ | Save 5% |
| Pro | $50 | 500 | 10.00¢ | Save 9% |
| Gold | $120 | 1,263 | 9.50¢ | Save 14% |
| Diamond | $300 | 3,333 | 9.00¢ | Save 18% |
By default your personal account is awarded 50 credits to start.
Caching Discounts
“Caching” is essentially the AI “remembering” parts of your conversation to work faster and more efficiently the next time. How it saves you money: When the AI uses this “memory” instead of processing everything from scratch, it costs you less — the cached portion is usually around 50% cheaper. When you use models that support caching (for example, OpenAI GPT‑5, GPT‑Realtime, or Claude Sonnet v4, which typically provide stronger caching behavior), you will benefit from these savings. These savings also apply in Conversation Mode. How to see savings: You don’t have to guess if you’re saving money. You can view your actual savings in the Dialog Report Card or the Admin → History section of your account, so administrators can review and validate the realized credit reductions.Token and Credit Calculation
When an interaction runs, several token metrics are tracked and used to determine the final number of credits billed.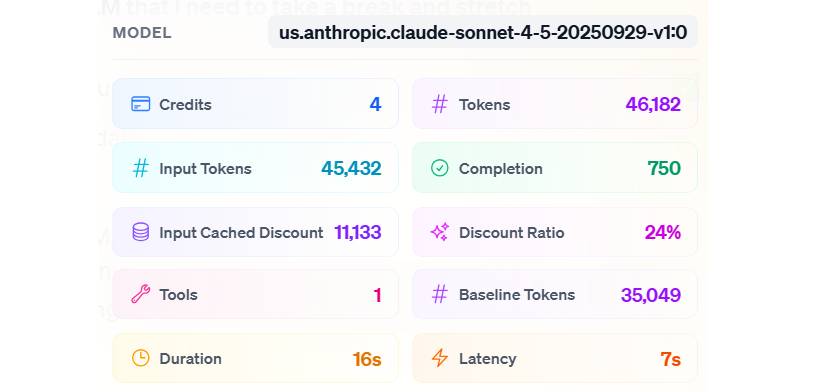
Definitions
TokensTotal number of tokens processed by the model, including both input and output. Input Tokens
Number of tokens sent to the model for the interaction (prompt, system instructions, tools, etc.). Input Cached Discount
Portion of the input tokens that are recognized as cached and therefore discounted from the billable input. These tokens still count toward usage, but not fully toward cost. Discount Ratio
Percentage discount applied to the cached portion of the input tokens. A higher ratio means a larger cost reduction from caching. Baseline Tokens
Final effective token count used to compute credits after applying the caching discount. This is the value that is converted into credits.
Example
In the example below, without any caching benefit, the interaction would have cost 5 credits. With caching enabled:- Some of the input is recognized as cached
- The Input Cached Discount is applied
- The Discount Ratio determines how much of those cached tokens are discounted
Completion
Content generated by the LLM counts toward Completion tokens (output). For most models that support caching, these completion tokens are generally around 10× more expensive than input tokens. It is important to note that caching is applied only to input tokens—completion tokens are never cached by the underlying models. To your direct benefit, Praxis AI does not introduce any surcharge or special markup for completion tokens:- Completion tokens are billed using the same pricing curve as input tokens.
- Caching discounts apply only to input tokens when the underlying model supports input caching.
- As a result, you get transparent, predictable pricing for all generated output, without hidden multipliers or extra completion-specific fees.
Credit Optimization
See Credits Optimization for ways to optimize your credit usage.Named User Subscription
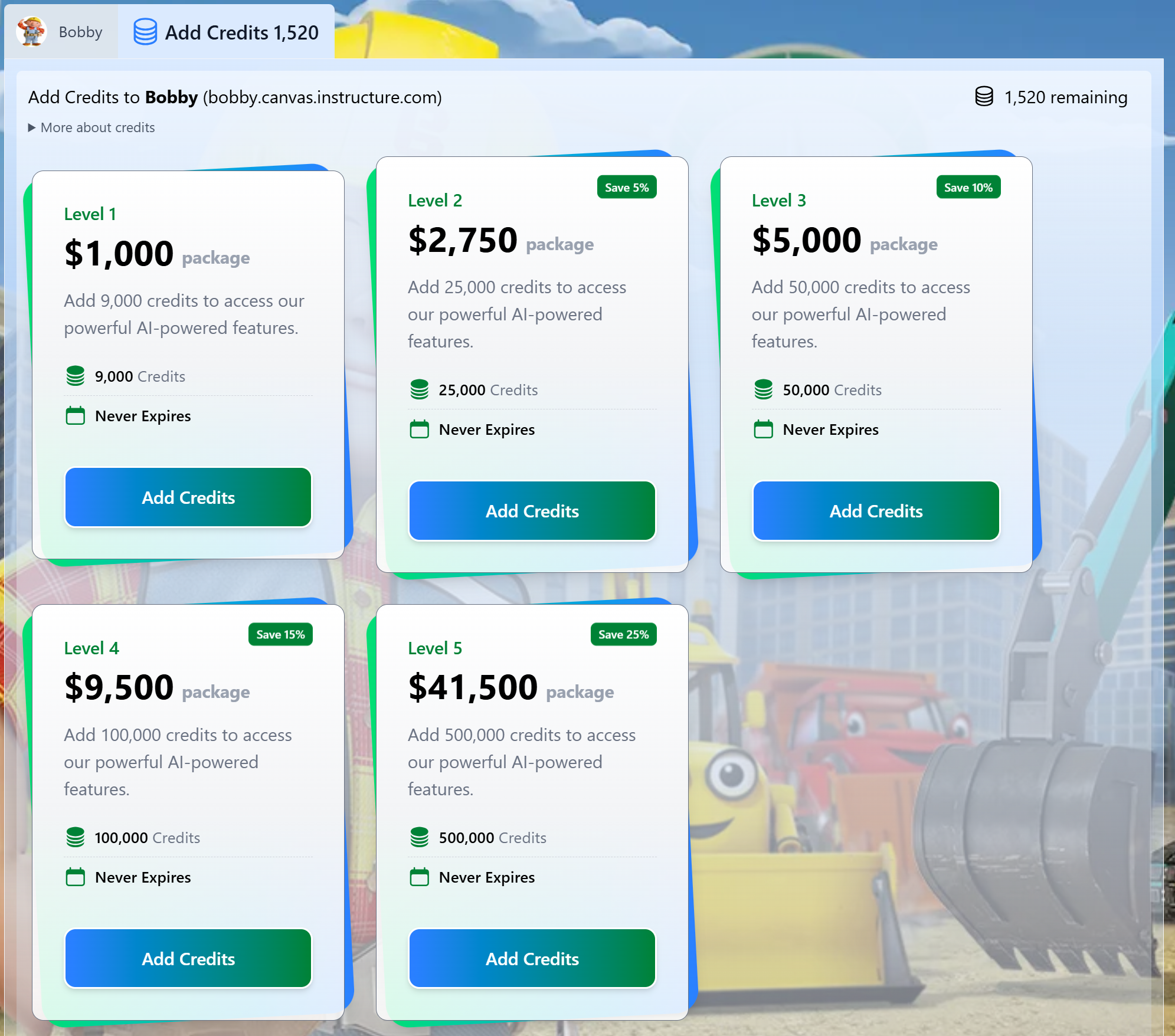
The Named User Subscription model is an annual contract that allows Client to purchase a per named user subscription that can be used anytime, anywhere, with an aggregated number of maximum credits based on the size of the population; calculated as one thousand (1,000) credits x number of named users. For example, a population of 500 named users would have a combined 500,000 credits to be used among all users each year. This model is perfect for schools, corporations, and other entities that want to pool credits on behalf of their users. Below is the volume breakdown:| Tier | Users | Description |
|---|---|---|
| 1 | Up to 1,000 | Annual subscription per named user |
| 2 | 1,001 to 5,000 | Annual subscription per named user |
| 3 | 5,001 to 10,000 | Annual subscription per named user |
| 4 | 10,001 to 15,000 | Annual subscription per named user |
| 5 | 15,001 to 50,000 | Annual subscription per named user |
| 6 | 50,001 to 75,000 | Annual subscription per named user |
| 7 | 75,000+ | Annual subscription per named user |