Instance Management
Instances are the core of your Praxis AI experience, allowing you to manage and interact with various digital twins.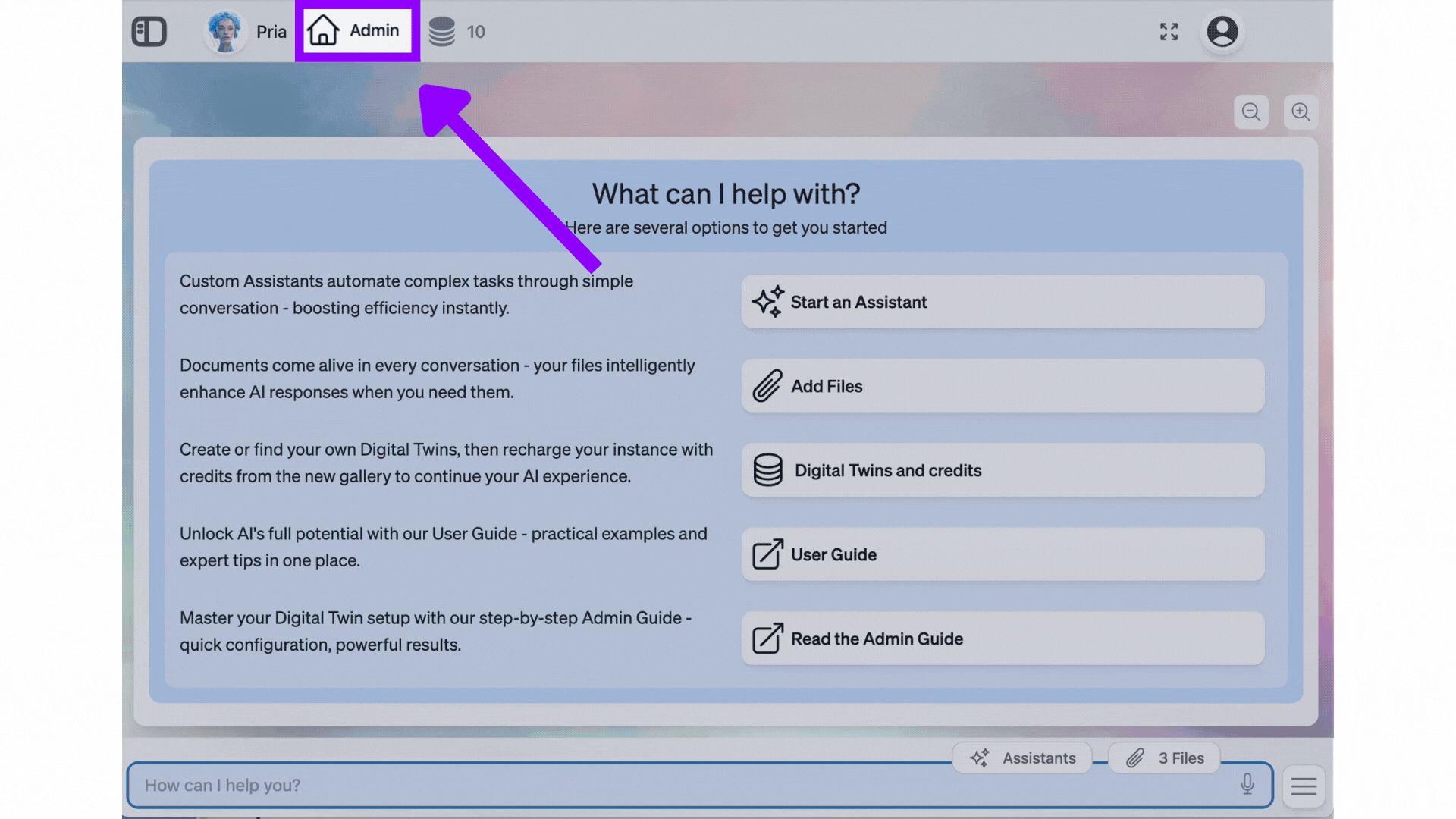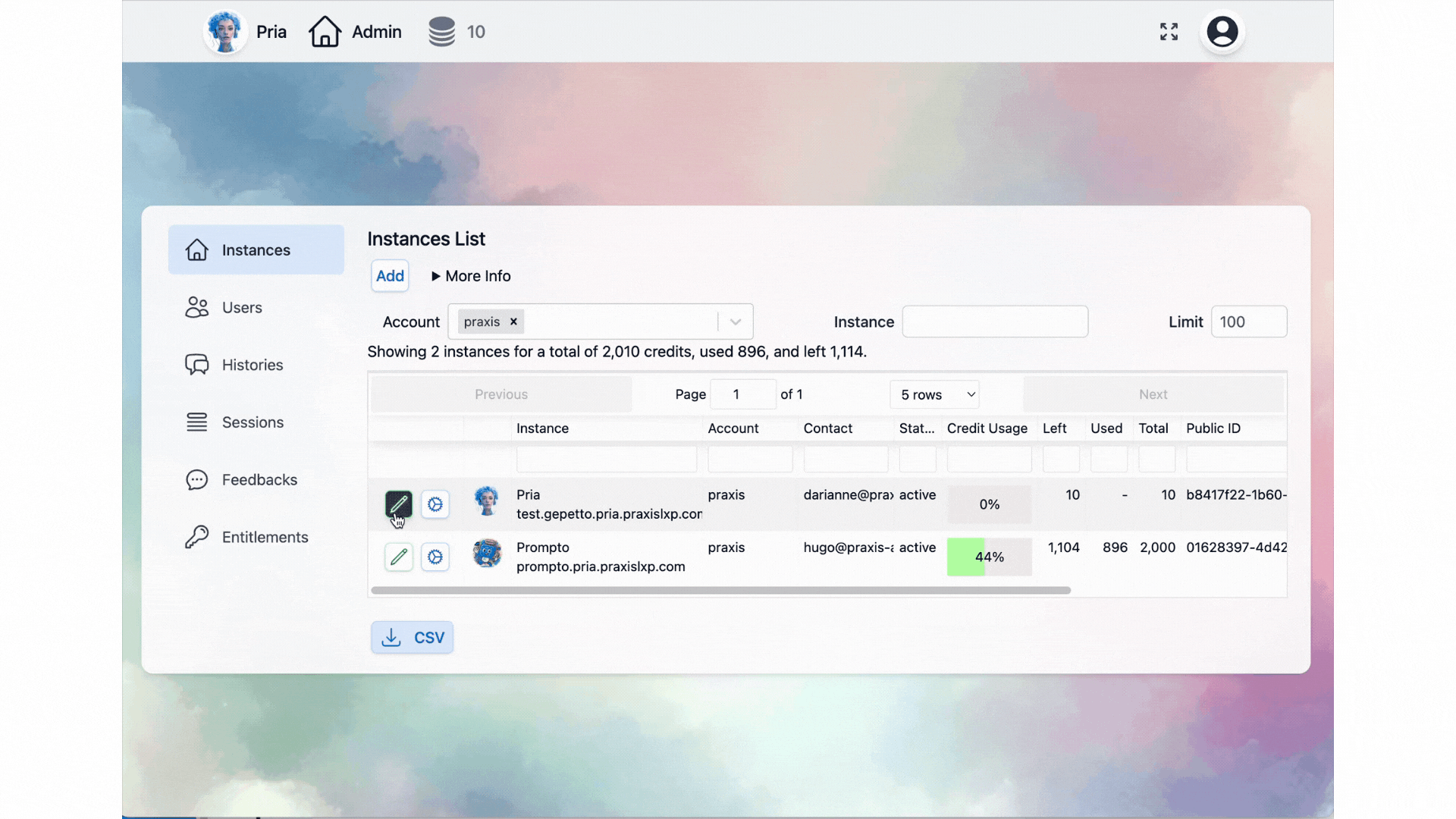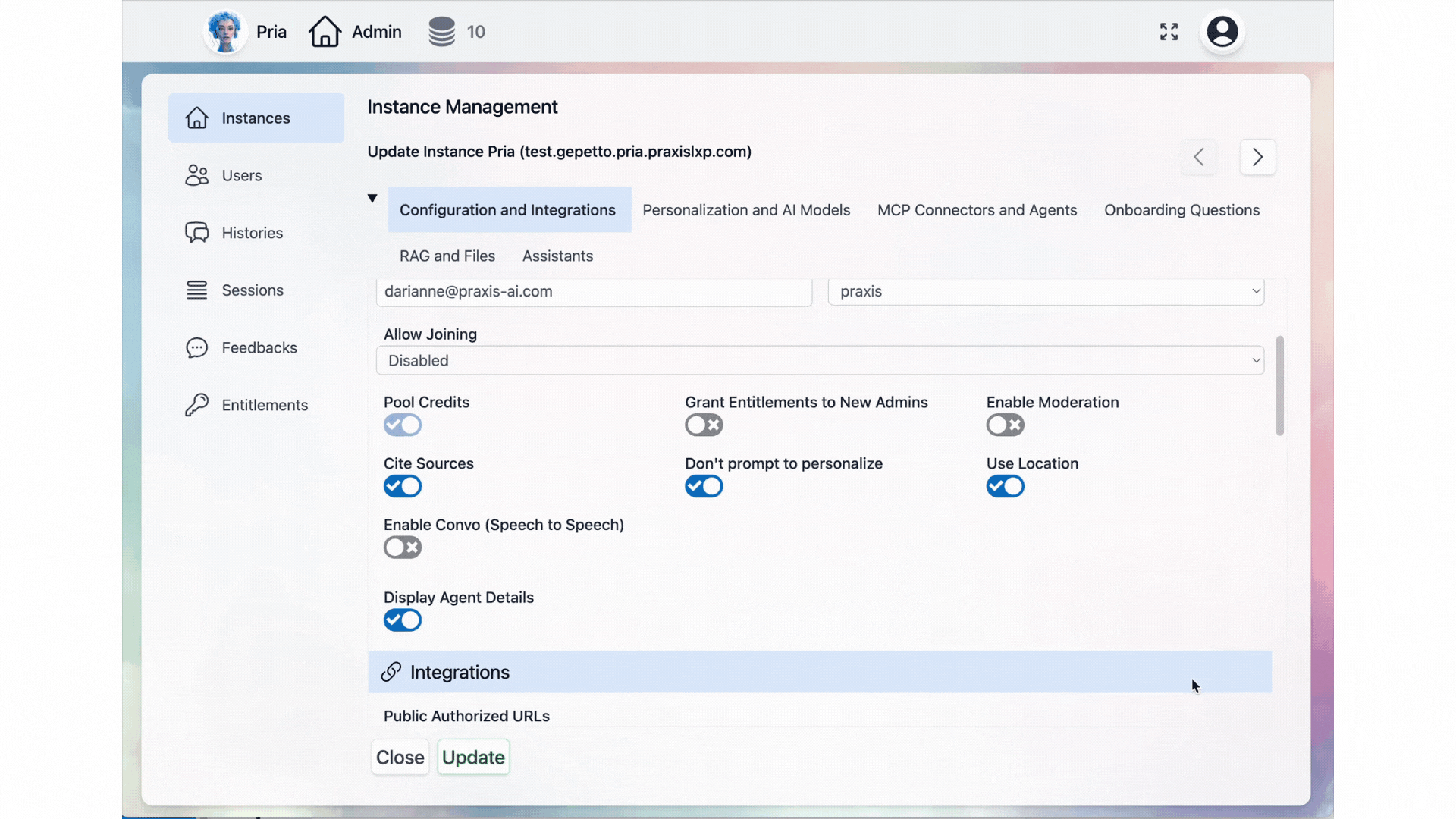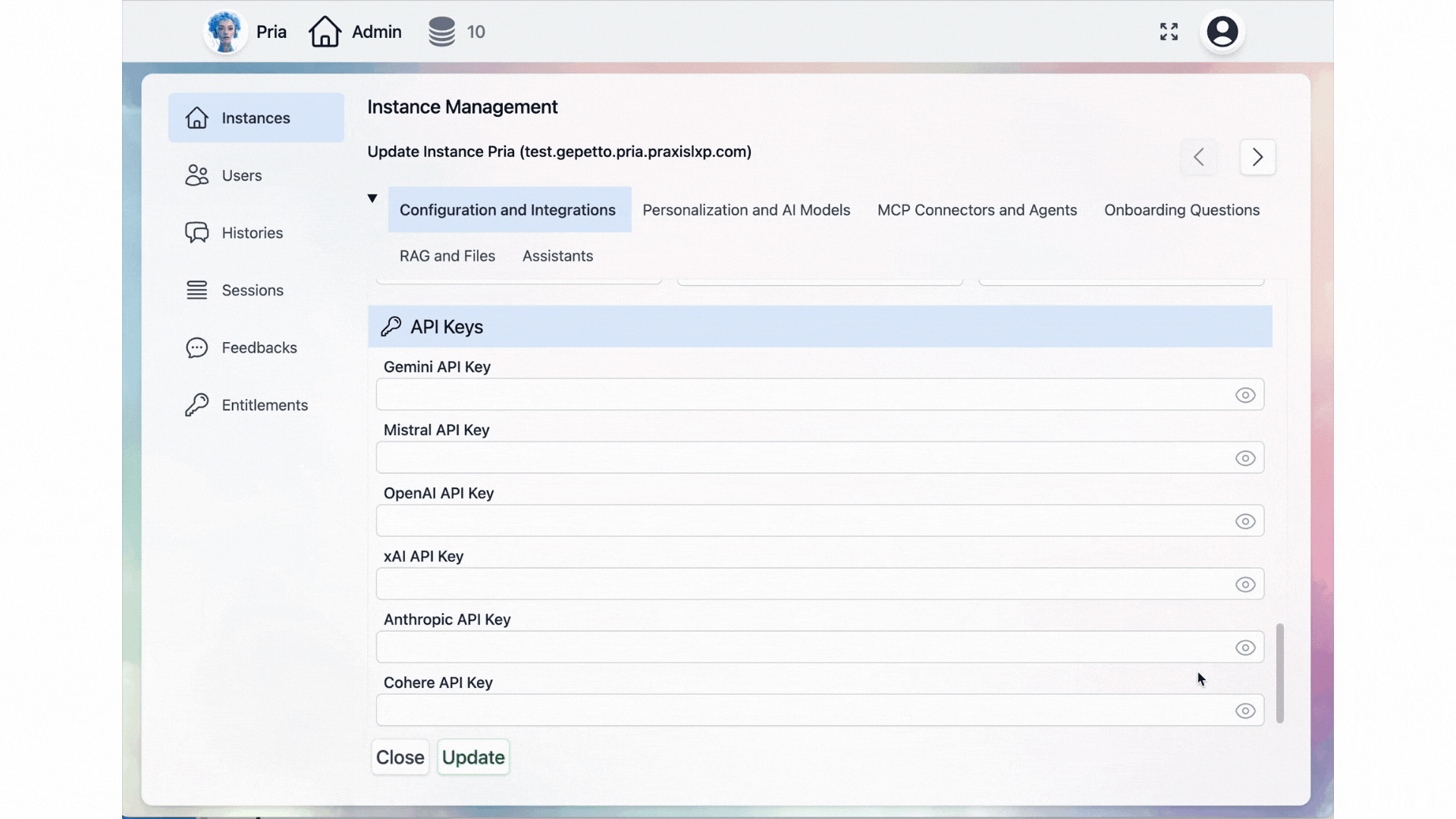
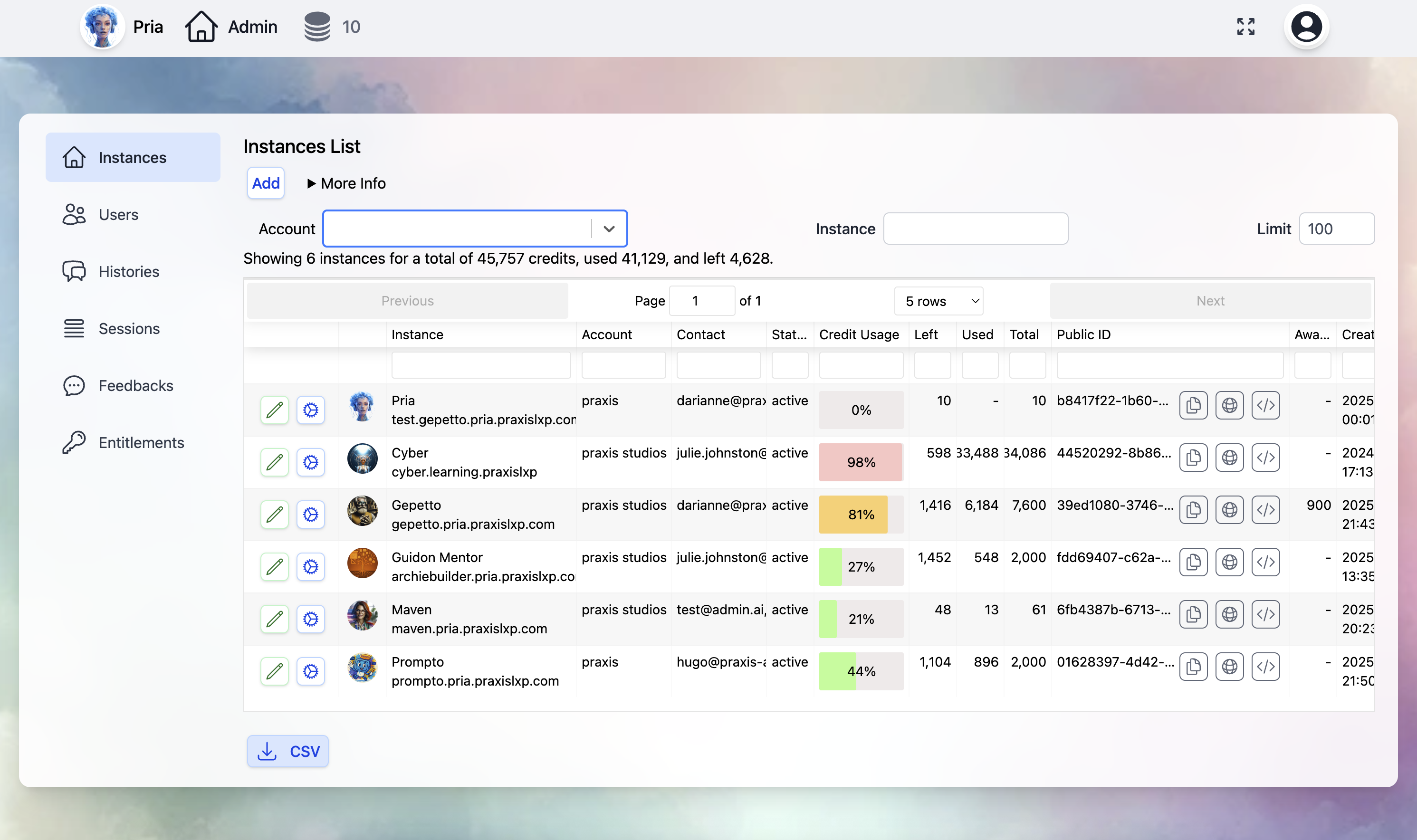
Viewing Instances
List of Instances
Instance Details
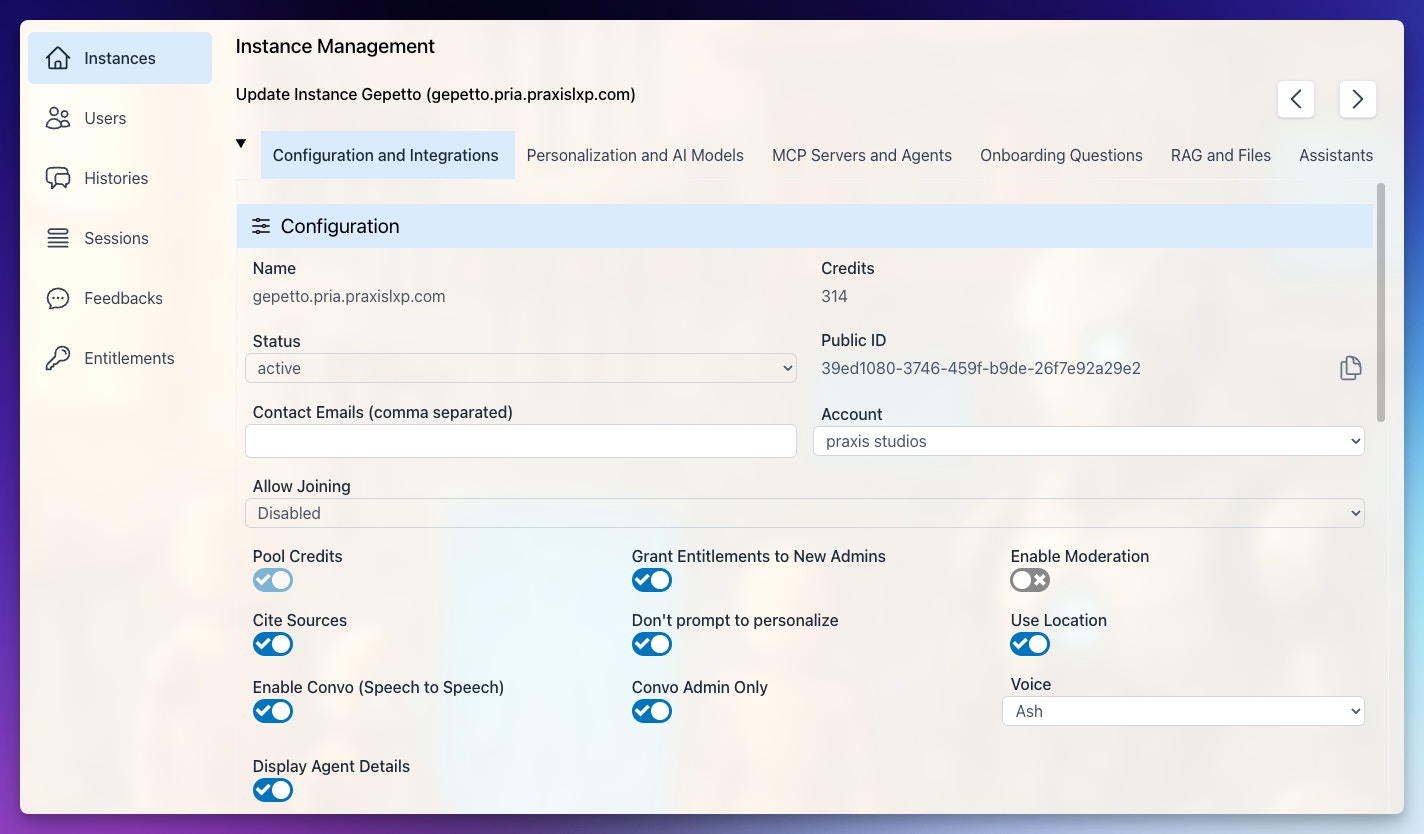
Name
Name
Instance Credits
Instance Credits
Status
Status
- Active — Instance is operational for all users
- Inactive — Instance is temporarily disabled
Public ID
Public ID
Contact Emails
Contact Emails
Account
Account
Allow Joining
Allow Joining
- Disabled — Users cannot self-join; they must be added by an administrator
- Account only — Only users within the same institutional account can join
- Everyone (public) — Anyone can join this instance
Joining Admin Only
Joining Admin Only
Pool Credits
Pool Credits
Credits Awarded to New Users
Credits Awarded to New Users
0 to disable automatic credit awards. This field is only visible when Pool Credits is disabled (i.e., users manage their own credit balance).Grant Entitlements to New Admins
Grant Entitlements to New Admins
Content Moderation
Content Moderation
Cite Sources
Cite Sources
Don't Prompt to Personalize
Don't Prompt to Personalize
Use Location
Use Location
Enable Convo (Speech to Speech)
Enable Convo (Speech to Speech)
Convo Admin Only
Convo Admin Only
Convo Enable Text Input
Convo Enable Text Input
Display Tools Details
Display Tools Details
Prevent Switching to Other Instances
Prevent Switching to Other Instances
Disable Clipboard for Users
Disable Clipboard for Users
- Text selection is disabled on AI responses and user inputs
- Copy keyboard shortcuts (Ctrl+C / Cmd+C) are blocked
- Copy-to-clipboard buttons are hidden
- Share link buttons are hidden
Disable Add Credits
Disable Add Credits
History Compaction
History Compaction
- As a conversation grows, Pria monitors the total token count
- When approaching the model’s context limit, older messages are grouped and summarized by an LLM
- The summaries replace the original messages, preserving key context while reducing token usage
- Base64-encoded data (images, files) is automatically stripped from compacted history
- Tool results are enriched with human-readable summaries before compaction
Knowledge & RAG Settings
These settings control how your Digital Twin retrieves information from the IP Vault (uploaded files, links, audio notes). The full reference — retrieval mode defaults (Disabled / Normal / KAG Fusion / Search Only), KAG enablement, chunk handling, thekmeanScore similarity threshold, embedding model selection, and file upload policies (disableFileUploadForUser, enableFileUploadForEmail, maxFiles, ignorePersonalVault) — lives on the dedicated Knowledge & RAG Configuration page.
On this Configuration tab you will also find the display toggles that decide what users see alongside each response:
- Display RAG Search Details — show which passages were retrieved and their relevance scores
- Display Thinking Details — show the model’s reasoning trace when thinking is enabled
- Display Tool Execution — show real-time progress as tools execute
- Display Agent Details — show the complete agent step-by-step breakdown
Memory Settings
The Digital Twin remembers facts about each user across conversations (memory parameters), and long conversations are automatically summarized to stay within the model’s context window (Compact History — see the History Compaction accordion above). For the memory model — personal vs. instance-shared memory, how rows are written during conversations, and how admins inspect or edit them — see Memory Parameters & Act As.Tool & Assistant Controls
Govern which tools and assistants are available to standard users on this instance.Disabled Tools
Disabled Tools
toolsDisabled Default: NoneA multi-select of platform tools that the Digital Twin should NOT use on this instance — e.g., disabling generate_image for a text-only academic instance, or hiding call_canvas when Canvas is not configured. Tools are matched by ID and excluded from the model’s tool list at request time, so even if the model “tries” to call them, the request is rejected upstream.Tool Result Size Limit
Tool Result Size Limit
toolResultsMaxChars Default: 60000Maximum number of characters returned by a single tool call. Longer results are truncated. Increase for instances that work with large documents or detailed API responses. Decrease to reduce token usage and protect against runaway tool output.Disable Assistants for User
Disable Assistants for User
disableAssistantsForUser Default: OffWhen enabled, regular users cannot access the Assistant Library or use custom assistants. Administrators retain full access. Useful when the Digital Twin should present a single unified persona rather than a menu of specialists.Disable Create Assistants for User
Disable Create Assistants for User
disableCreateAssistantsForUser Default: OffWhen enabled, regular users can use assistants but cannot create new ones. All assistants are admin-authored. Useful for curated deployments (curriculum, customer support).Disabled Assistants
Disabled Assistants
assistantsDisabled Default: NoneA multi-select of specific assistants that should be hidden from the assistant library on this instance, even if they exist in the catalog. Use this to retire assistants without deleting them.Enable Assistants for Email
Enable Assistants for Email
enableAssistantsForEmail Default: EmptyWhitelist of email addresses that are allowed to use assistants when assistants are otherwise disabled for users. Useful for granting authoring access to a small pilot group.Realtime Voice (Convo Mode)
The high-level voice toggles — Enable Convo (Speech to Speech) and Convo Admin Only — are covered in the Instance Management accordions above. Provider choice (OpenAI GPT-Realtime, Gemini Live, ElevenLabs, Anam Avatar, xAI Voice), voice selection, voice activity detection, noise reduction, transcription language, and avatar customization all live in the Personalization tab — see Realtime Voice & Avatars for the full setup guide.Provider API Keys (Bring Your Own Key)
By default, the Digital Twin uses Praxis-managed credits for every AI provider. When you provide your own API key for a provider, the Digital Twin routes that provider’s requests directly to your account — bypassing Praxis credits for that provider and giving you full control over billing, rate limits, and model availability. Keys can be supplied for OpenAI, Anthropic, Google Gemini, Mistral AI, xAI, Stability AI, Cohere, DeepSeek, OpenRouter, and InferX, plus the voice/avatar providers ElevenLabs, Anam, and LemonSlice (which also take an Agent/Avatar ID). The per-provider fields and key-generation links are in the API Keys section of the Integrations tab, below.MCP Servers
Configure external Model Context Protocol (MCP) servers that the Digital Twin can call as tools. MCP is the open standard for connecting LLMs to external systems — your Digital Twin can use MCP servers as additional tool sources alongside Pria’s built-in tools.Enable MCP Server
Enable MCP Server
mcpServerEnabled Default: OffMaster switch for outbound MCP connections from this Digital Twin. When enabled, configured MCP servers appear in the tool catalog and are invoked alongside built-in tools.MCP Server Secret
MCP Server Secret
mcpServerSecretUnique authentication token used when this Digital Twin exposes itself as an MCP endpoint (inbound MCP). Generated automatically; can be rotated. Configure third-party MCP clients with this secret to call your Digital Twin as an MCP source.Advanced Configuration
These settings control fine-grained behavior of your instance. Most administrators can leave these at their default values.UI Customization
UI Customization
Integrations
Public Authorized URLs
Configure the URLs authorized to access your instance for secure integration with external platforms. Example for Canvas Integration:LTI Contexts
LTI (Learning Tools Interoperability) contexts are automatically populated when you connect an LTI placement to your digital twin instance. Key Features:- Automatic Population: Contexts are created when LTI placements are established
- Instance Memory: The system remembers which instance to launch when accessing your digital twin through LTI or Canvas theme-based integration
- Easy Management: Remove placements directly from this list or through your profile page
- Remove the placement from the LTI Contexts list, or
- Navigate to your profile page for additional management options
Google Workspace
Enable Google Workspace services (Gmail, Drive, Calendar, Sheets, Docs, Slides, Meet, Classroom) for your Digital Twin from this section. You choose between two identity models: each user connects their own Google account, or you turn on Use Digital Twin Identity and connect one shared institutional account for everyone via the Connect Google Account OAuth flow. The full setup walkthrough — the service capability table, service dependencies, the two connection models, and the connect/disconnect flow — is on the Cloud Services page; see also the Google Workspace Integration guide for the authorization model and troubleshooting.ElevenLabs
Connect your Digital Twin to an ElevenLabs Conversational AI agent to enable voice capabilities — both for Pria’s built-in Convo Mode and for embeddable client widgets. Two credentials are entered in this section:- ElevenLabs Agent ID — the Agent ID from your ElevenLabs Conversational AI agent
- ElevenLabs API Key — authenticates requests between ElevenLabs and your Digital Twin; must match the key in your ElevenLabs agent’s Custom LLM settings
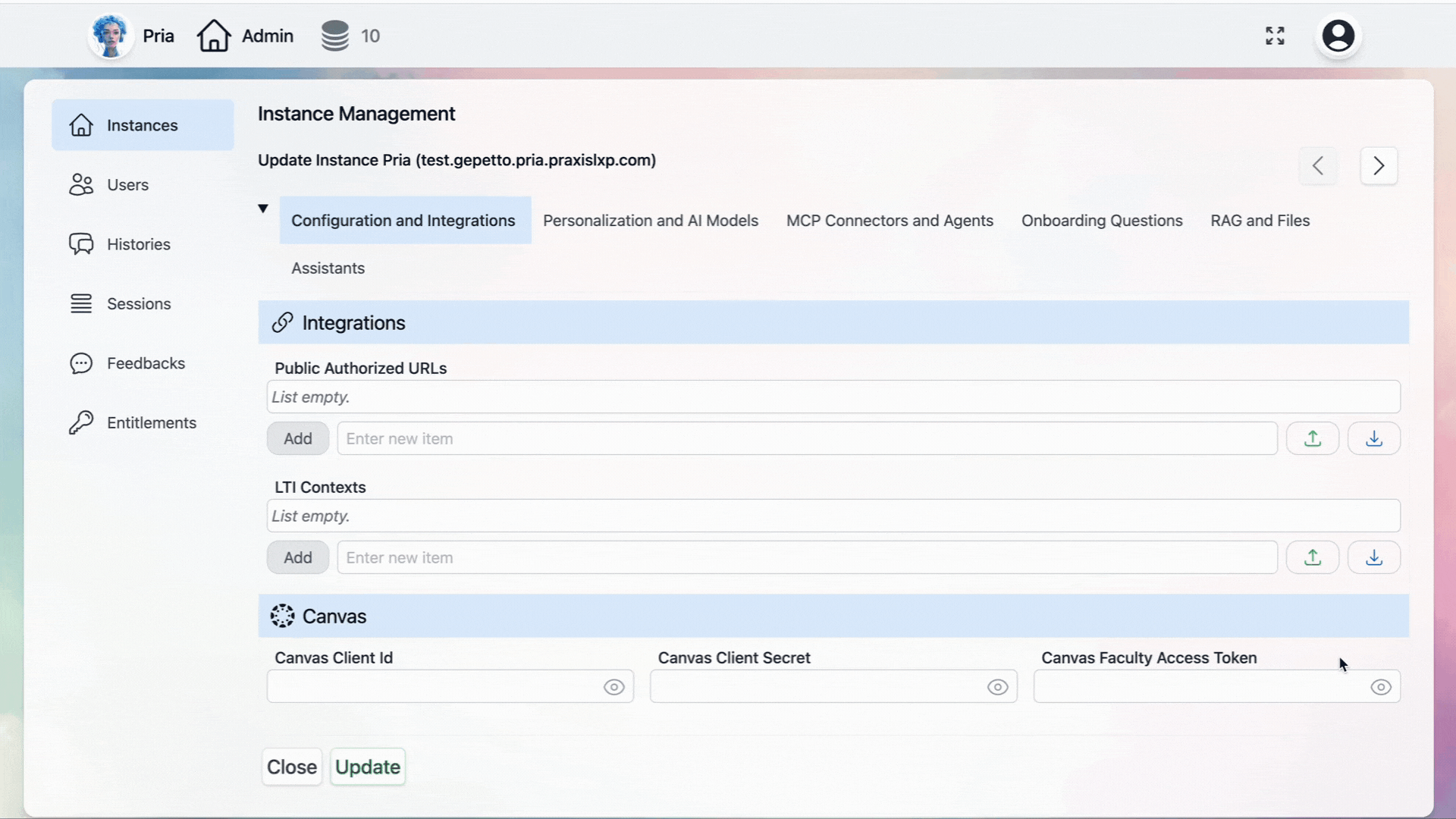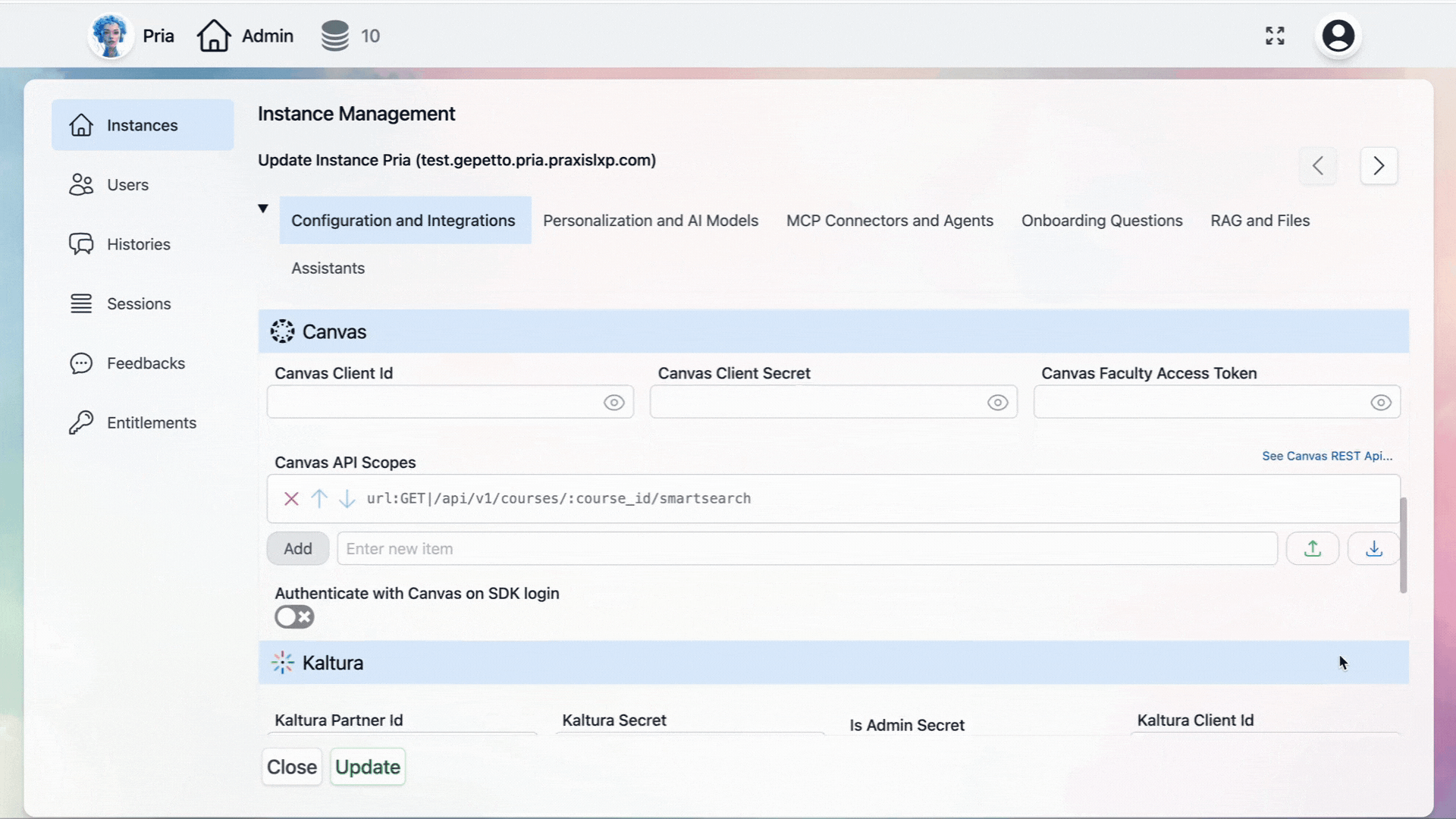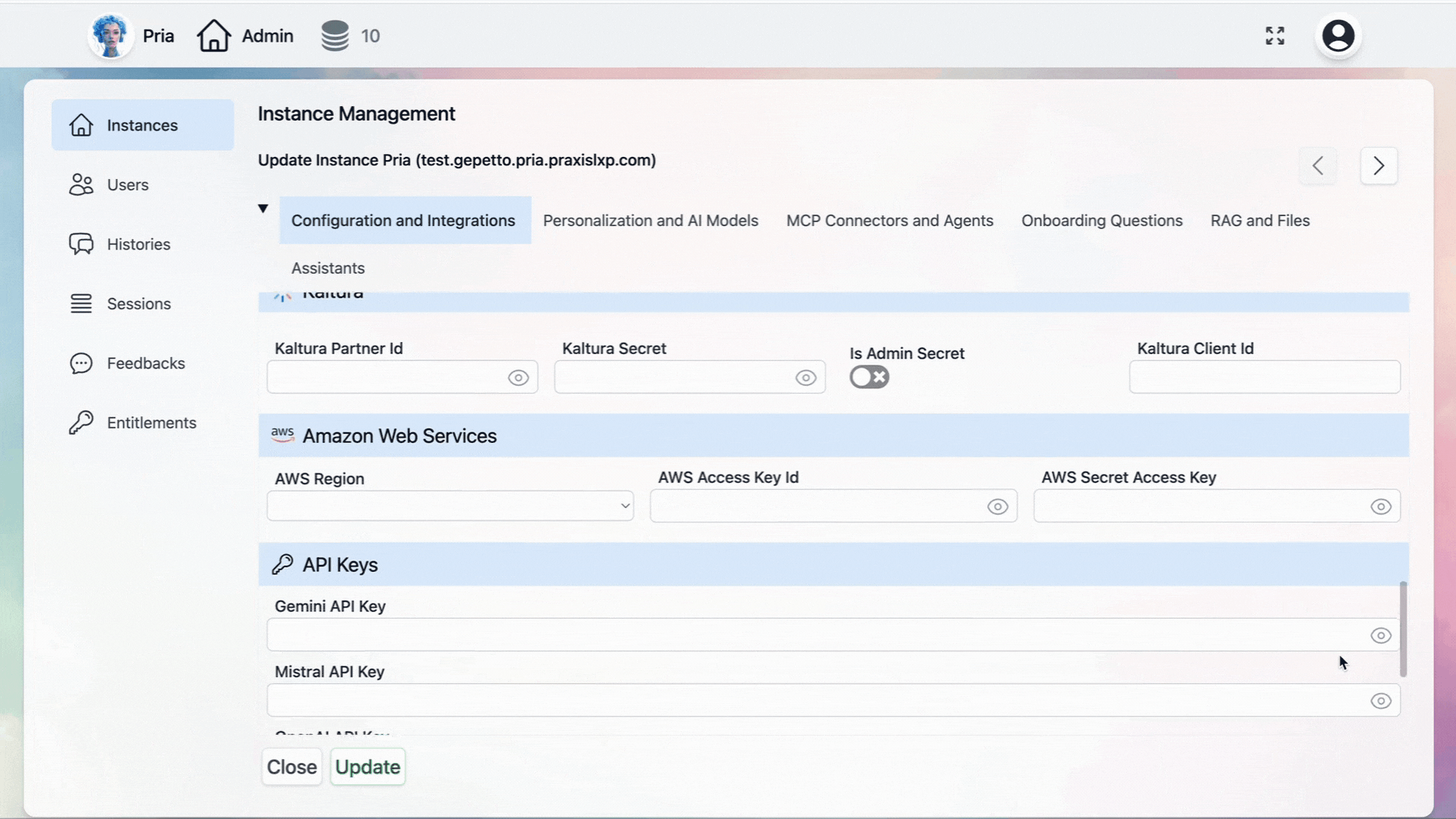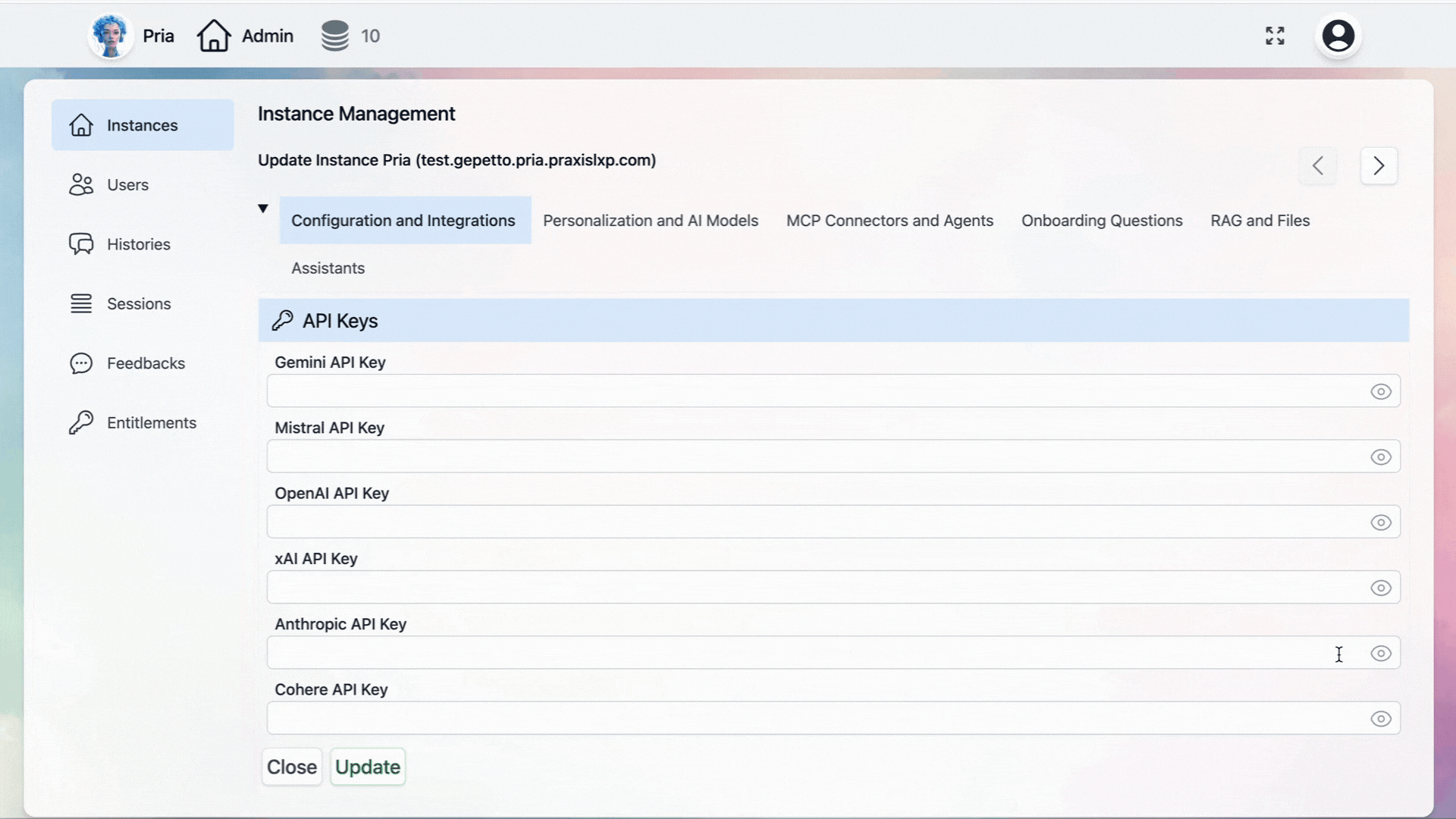
Canvas
Connect your Digital Twin to Canvas LMS so it can query courses, assignments, grades, and more through the Canvas REST APIs. If these credentials are not configured, thecall_canvas and search_canvas tools will be unavailable.
Canvas Client ID
Canvas Client ID
10000000000217). This is generated when a Canvas administrator creates an API-type Developer Key under Admin → Developer Keys.One Developer Key can be shared across multiple Digital Twin instances within the same institution.Canvas Client Secret
Canvas Client Secret
Canvas Faculty Access Token
Canvas Faculty Access Token
Canvas API Scopes
Canvas API Scopes
url:GET|/api/v1/courses/:course_id/smartsearchScopes must be configured in two places — on the Canvas Developer Key and here in your Digital Twin instance. If a scope is missing from either location, the API call will be rejected.See Canvas Scopes Reference for the full list of available scopes and a starter configuration.Authenticate with Canvas on SDK Login
Authenticate with Canvas on SDK Login
Kaltura
Connect your Digital Twin to the Kaltura Video Platform to enable video search, playback, and media-related interactions within conversations. Enter your Kaltura Partner ID and API Secret (plus a Client ID when using a user-level secret) in this section — see Cloud Services for the field reference and where to find each value in the Kaltura Management Console.Amazon Web Services (AWS)
Connect your Digital Twin to your own AWS services — primarily Amazon Bedrock for AI model access and Amazon S3 for storage. Administrators configure their own IAM credentials so the Digital Twin uses their AWS account directly, allowing access to Bedrock foundation models (e.g., Claude, Titan, Llama) and S3 storage under your organization’s billing and security policies.AWS Region
AWS Region
- us-east-1 (N. Virginia) — Broadest Bedrock model availability
- us-west-2 (Oregon) — Good Bedrock coverage
- eu-central-1 (Frankfurt) — European data residency
- ap-southeast-1 (Singapore) — Asia-Pacific
AWS Access Key ID
AWS Access Key ID
AWS Secret Access Key
AWS Secret Access Key
API Keys
By default, your Digital Twin uses Praxis-managed credits to access AI models. When you provide your own API keys, the Digital Twin routes requests directly to that provider using your account and token pool — giving you full control over billing, rate limits, and model availability. This is especially useful for organizations that already have enterprise agreements with AI providers or want to manage usage and costs independently.OpenAI API Key
OpenAI API Key
Anthropic API Key
Anthropic API Key
Gemini API Key
Gemini API Key
xAI API Key
xAI API Key
Mistral API Key
Mistral API Key
DeepSeek API Key
DeepSeek API Key
Cohere API Key
Cohere API Key
Related
- Knowledge & RAG Configuration — Retrieval modes, chunk handling, embeddings, KAG analysis model, upload policies
- Realtime Voice & Avatars — Provider catalog, voice tuning, avatar configuration
- Cloud Services — Google Workspace and Kaltura setup
- MCP Servers — Inbound and outbound Model Context Protocol setup
- Memory & Act As — Per-user memory, shared memory, impersonation
- AI Models — Provider catalogs, BYOM, reasoning effort, prompt caching
- Personalization — Identity, avatar, branding, model assignments
- Content Moderation — Per-message safety screening
- Onboarding Questions — Guided personalization for new users