What knowledge retrieval does
Behind the scenes, every file you put in your IP Vault (your personal vault, your Digital Twin’s shared vault, and the account-wide vault) is processed and indexed. When you ask a question with retrieval turned on, Pria:- Searches the indexed content for the passages most relevant to your question.
- Hands those passages to the model as context.
- The model composes an answer that quotes or paraphrases your material and cites the source files.
Knowledge retrieval is the foundation of Pria as a knowledge worker tool. Most institutions leave it on by default.
Where the Knowledge controls live
Open the [+] (Actions) menu to the left of the input pill and choose Knowledge. The panel expands inline with everything that shapes a reply’s context: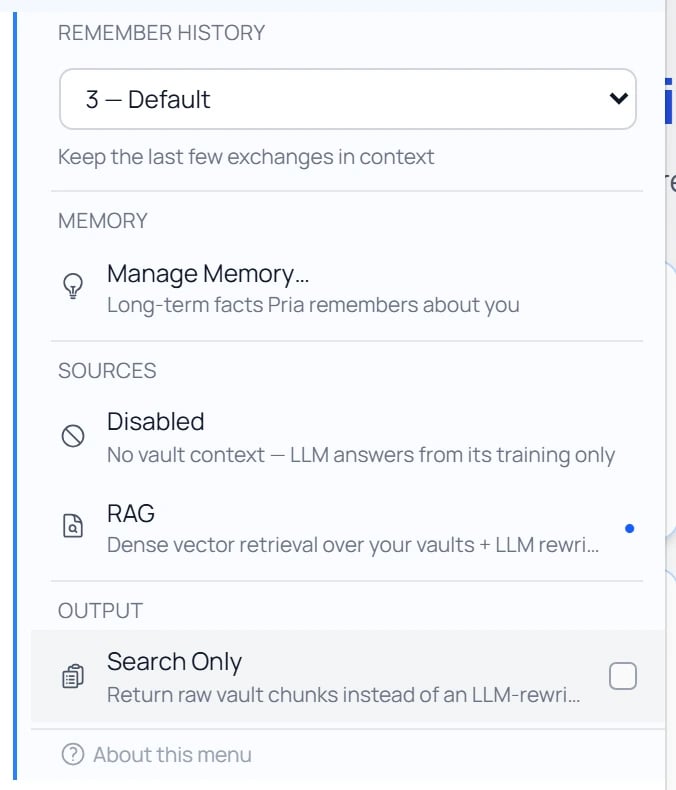
- Remember History — how many recent exchanges stay in context (see Conversation History).
- Manage Memory — long-term facts Pria remembers about you (see User Memory).
- Sources — the retrieval mode (below).
- Search Only — an output toggle (below).
Knowledge isn’t a separate sidebar panel — it’s a section of the [+] Actions menu, so it’s always one click from the composer while you chat.
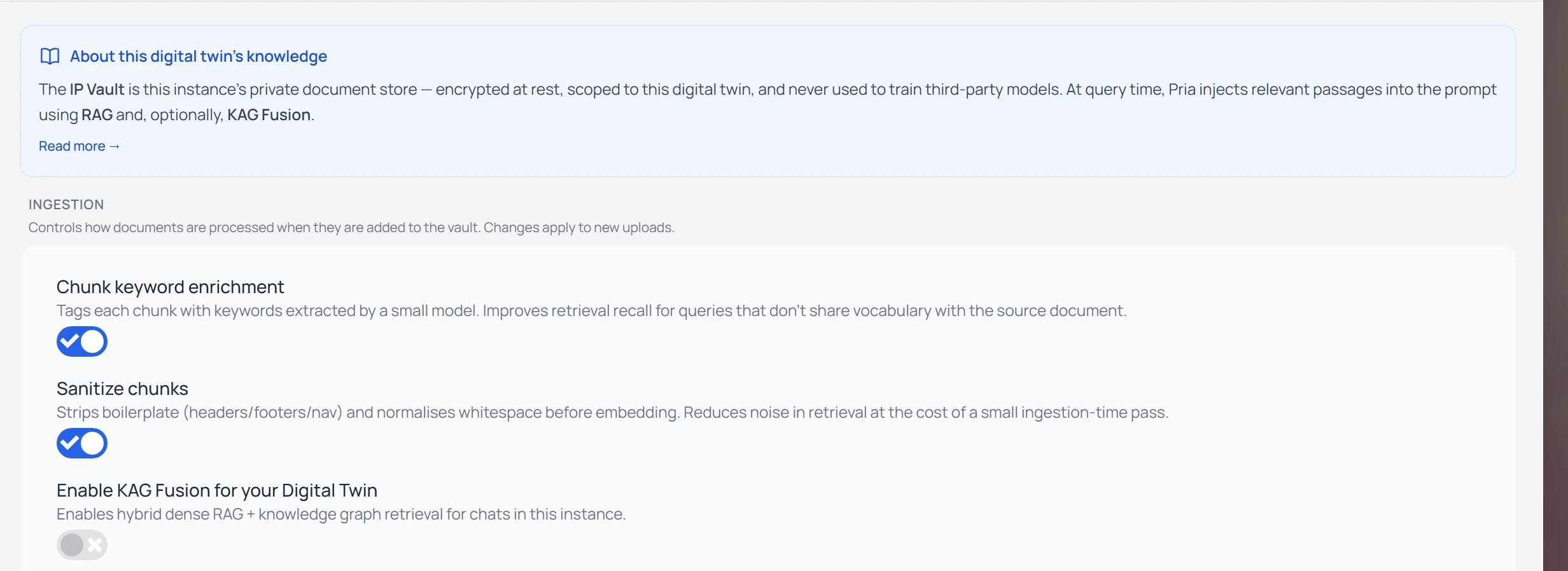
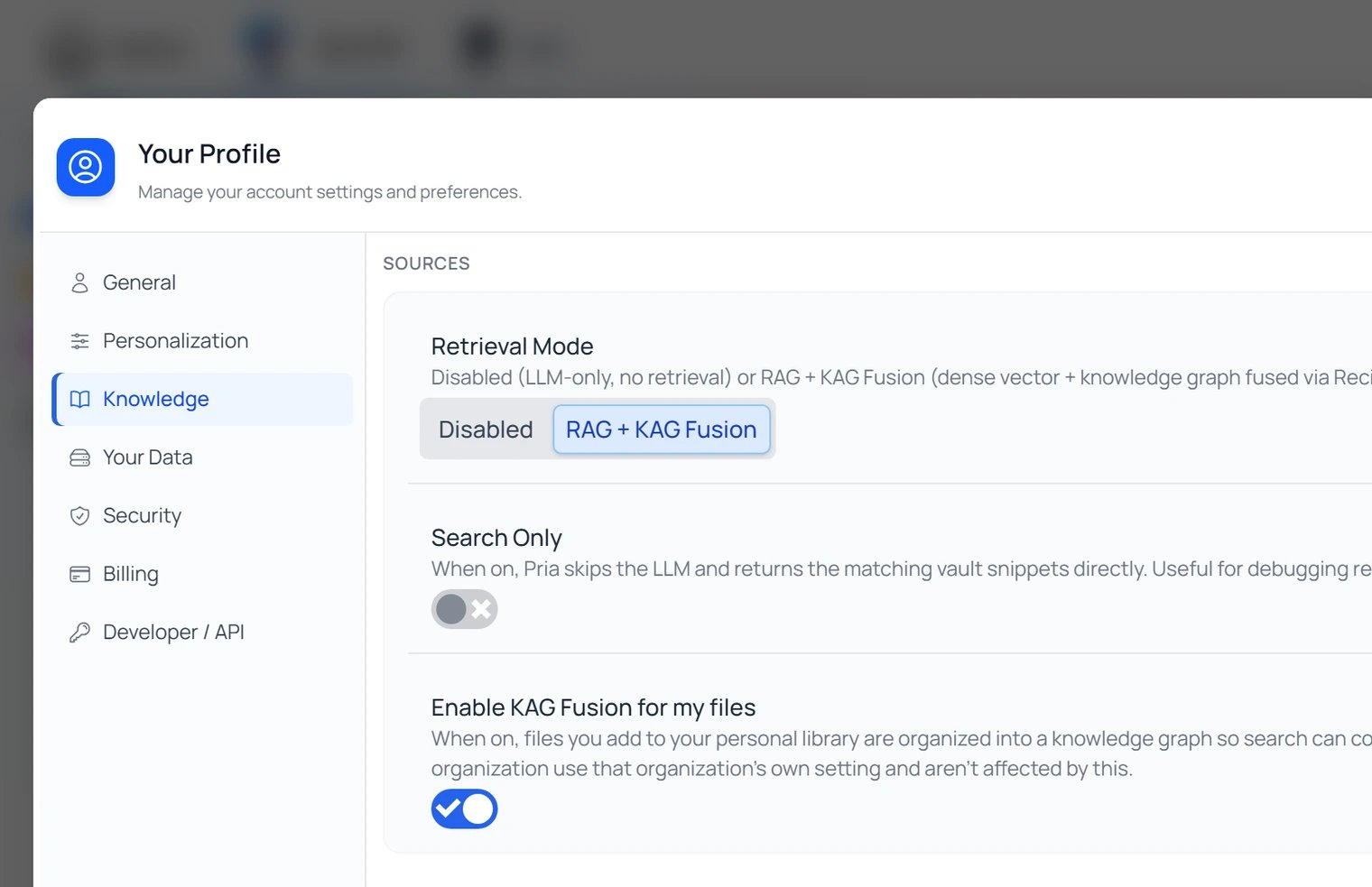
Sources: how Pria searches
The Sources radio is the core choice. It has two states — and the “on” state quietly upgrades itself when a knowledge graph is available.Disabled
No retrieval at all. The model answers from its training data alone, with no reference to your files. Handy for off-topic questions or when you specifically want the model’s own knowledge.
RAG
Retrieval on. Pria runs a dense vector search over your file chunks to find the passages most similar in meaning to your question, then feeds them to the model. This is the everyday default for “what does this say about X” questions.
RAG + KAG Fusion
What RAG automatically becomes when the vault you’re searching has a knowledge graph. Pria adds a graph-search leg — entities (people, organisations, concepts) and the relationships between them — and fuses the two ranked lists. Better for “how does X relate to Y” or “who works on Z” questions where the answer is structural. You don’t pick this separately; turning Sources on uses Fusion wherever a graph exists, plain RAG otherwise.
Search Only (toggle)
A separate Output toggle, not a source. With it on, Pria returns the matched passages exactly as the model would have seen them — without calling the model to write a reply. Useful when you want to skim the raw hits and pick your own quote. It only applies while Sources is on.
So the menu is really two settings, not four peers: a Sources radio (Disabled / on) and a Search Only output toggle. “Normal RAG” and “KAG Fusion” are the same on state — Fusion simply kicks in when a graph is available.
When to use each
Leave Sources on (RAG / Fusion) for…
Leave Sources on (RAG / Fusion) for…
- “What does the policy say about X?”
- “Summarise the second chapter.”
- “Find every place we mention vendor Y.”
- “How are X and Y related?” / “Who else works on Jane’s projects?” — these lean on the Fusion graph leg when one’s available.
- Most everyday questions where the answer is somewhere in your material.
Turn on Search Only for…
Turn on Search Only for…
- Skimming for primary sources before writing your own draft.
- Verifying a claim — get the passages without an LLM rephrasing.
- Auditing what the retrieval layer is actually seeing.
- Quick lookups where you trust your own reading over a synthesised answer.
Set Sources to Disabled for…
Set Sources to Disabled for…
- General knowledge questions unrelated to your files.
- Comparing Pria’s “off-the-shelf” answer to a grounded one.
- Speed runs where you don’t need the retrieval step at all.
- Diagnosing whether a wrong answer was caused by retrieval picking the wrong passages.
Showing or hiding retrieved passages
When retrieval runs, Pria can show you exactly what it pulled in — a collapsible panel beneath each answer, so you can verify the reply against its sources. Whether the panel appears is governed by the Display RAG/KAG Search Details toggle under Settings → Instance → Personalization → Display Details (the same place as the thinking-display toggles). In Search Only mode the passages are the entire response — there’s nothing to hide them under.KAG / RAG Search Results
Expand the KAG Search Results (or RAG Search Results) disclosure at the foot of a reply to see every passage that fed the answer. Each row shows the source file (and segment), a preview of the matched text, its Relevance score, and its Length, with numbered citations you can click to open the original.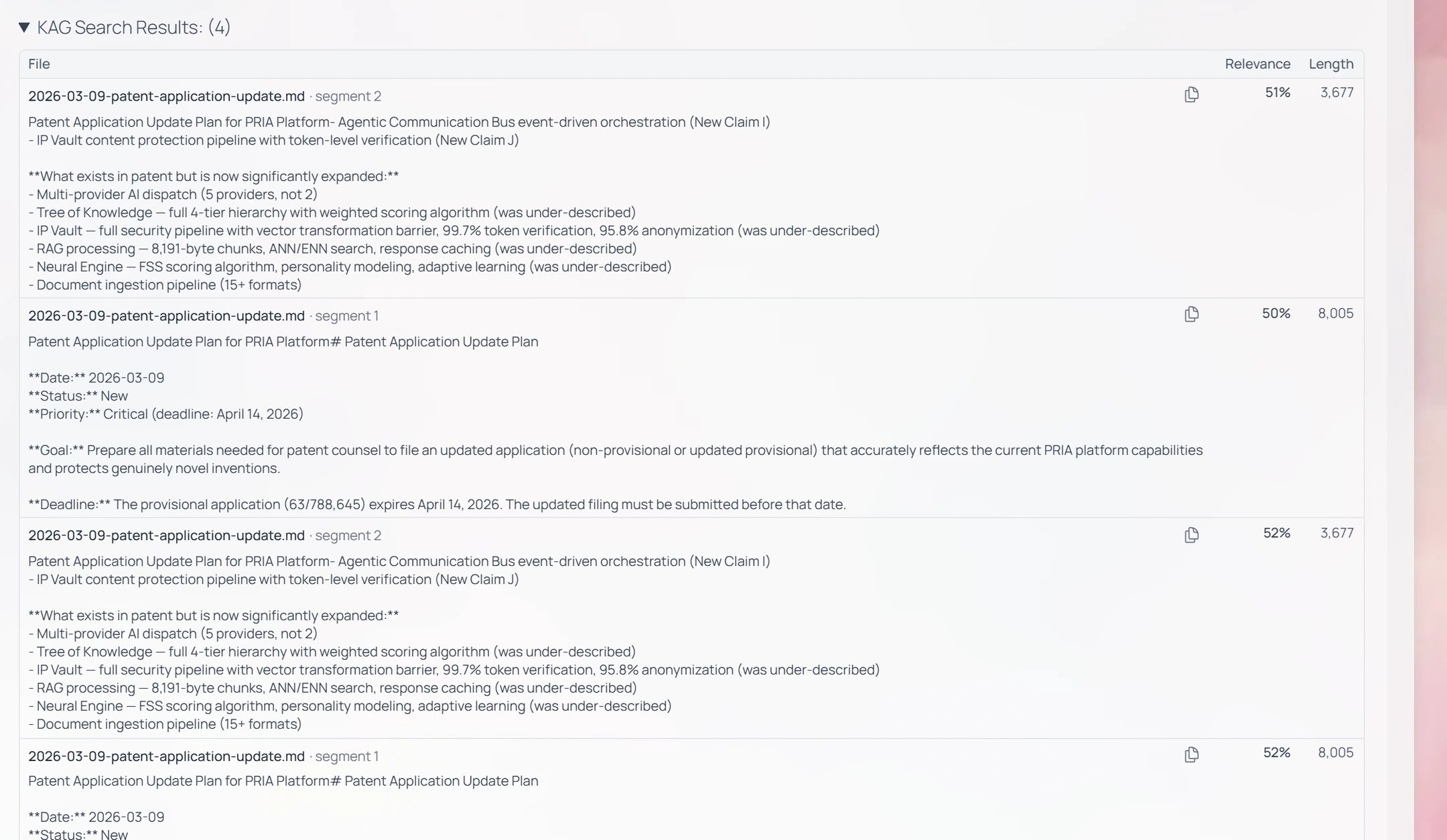
patent-application-update.md, scored ~50–52% relevant — the answer is built from those passages, and the citations jump straight to them.
Agent Details — what ran
When a reply also runs a tool — image generation, web search, an MCP connector, code — a separate Tool Details (Agent Details) disclosure appears. Expanded, it shows, per call: the tool name, a Success / failure status, the execution duration, the Arguments it was invoked with, and the Response it returned.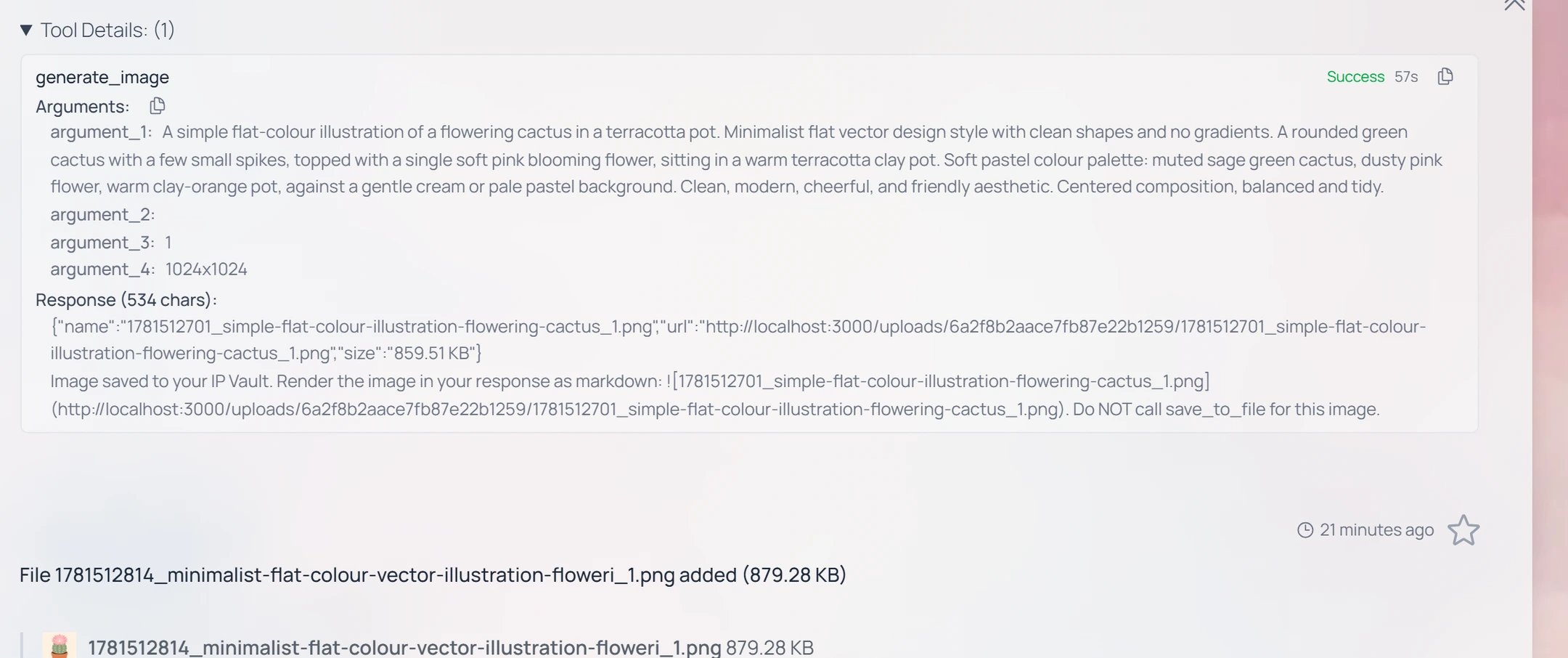
File scope: which vault gets searched
Every retrieval call looks across the vaults you have access to:
All three are searched concurrently and their results merged. See Managing Files for how to upload, mark shared, or move files between scopes.
An Admin can configure a Digital Twin to ignore your personal vault when chatting in that twin — useful for keeping personal notes out of an enterprise context. When that’s set, personal files stay searchable from the standalone “Personal Pria” but are invisible while you’re inside the institution twin.
Limitations
- Confidential files stay locked for everyone but their owner. A file marked Confidential can still lend its knowledge to answers, but other members never see its details — retrieval shows them a ”🔒 CONFIDENTIAL” marker and a short redacted snippet instead of the document. Only the owner gets full citations and preview. See What Confidential really means.
- Very recent uploads may still be indexing. Large PDFs, audio, and video files take a few minutes to extract, chunk, and embed. If a brand-new file isn’t appearing in retrieval yet, give it a moment and check Files for processing status.
- Disabled skips ALL files. Don’t leave Sources off by accident if you actually need grounded answers — your replies will go back to “general knowledge only”.
- Fusion needs RAG. The graph leg always sits on top of the dense RAG leg; there’s no “graph only”. With Sources disabled, neither runs.
- Search quality depends on file quality. Scanned PDFs without OCR, password-locked files, and corrupt uploads can’t be indexed. Check the file status in the IP Vault to see what’s processed.
Related
- IP Vault — what the vault is and how scopes work.
- Managing Files — uploading, organising, sharing, deleting.
- Audio Notes — voice memos that flow through the same retrieval pipeline.
- Conversation History — the Remember History control in the same menu.
- User Memory — the Manage Memory link in the same menu.
- Reasoning & Thinking — combine high effort with grounded retrieval for the best research answers.